Please head over to my new(/very old – you’ll see what I mean when you get there) blog, The Bierwayfarer. I’ve started to add GIS data on corpse roads there, and this is highlighting some of the problems with mapping fuzzy historical data in GIS. There’s a new post there highlighting some of these, and GIS data for the first three corpse roads.
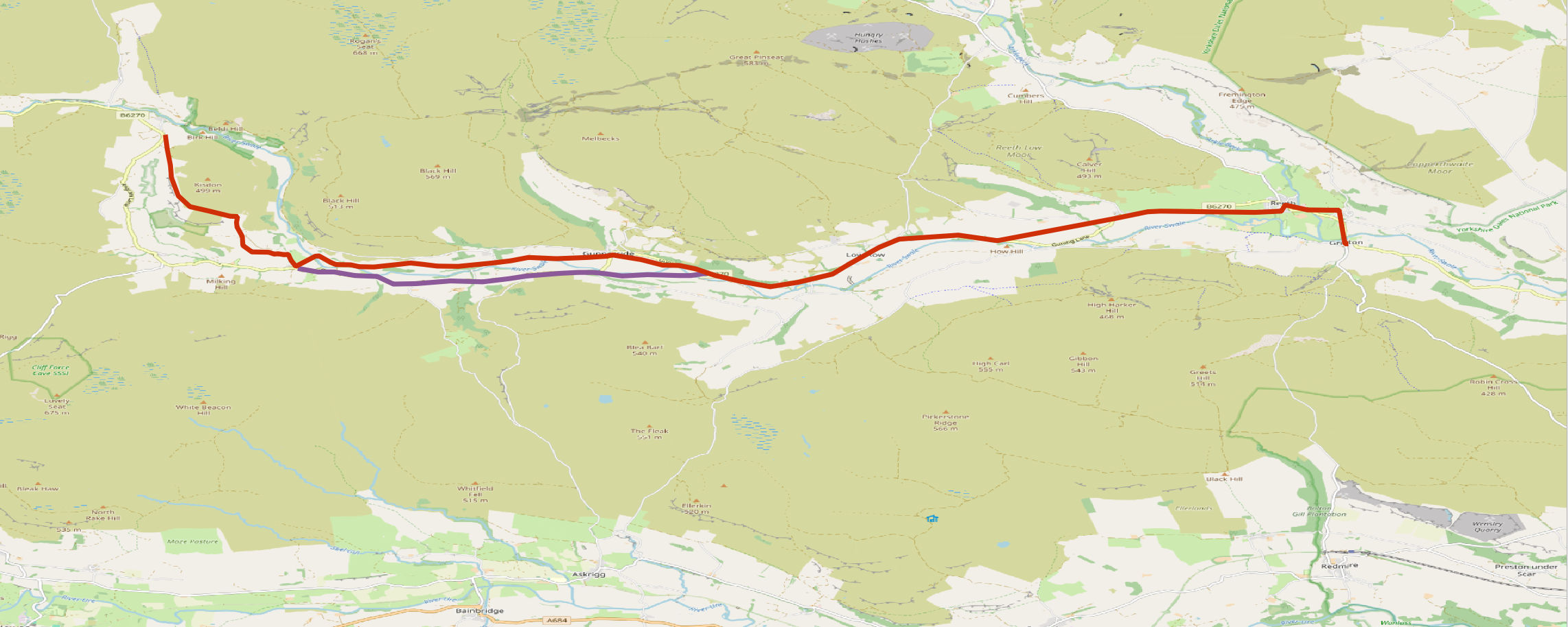
This is my latest paper on the subject, which discusses in detail the Swaledale Corpse Path (see map below). It seems to me that that corpse path folklore can be tied directly to traditions such as the “Lyke Wake Dirge”, as recorded by John Aubrey; and is often seen through the lens of later writers who were deeply suspicious of papist superstition, which was linked to moral and spiritual degeneracy.
On the way in to work on Tuesday of last week, I dashed off a slightly grumpy LinkedIn post highlighting and decrying the use of AI to write PhD supervision enquiries. Here it is in full:
I am getting more and more enquiries for PhD supervision which have clearly been written using AI. It is very easy to spot. It starts with an abstract summary of my research, highlighting a few of my publications and how transformative the writer has found them. One recent enquirer told me how inspiring they had found one of my papers which has not been published yet, but which appears as in press on my profile. It is that (painfully) obvious. After that is a similarly abstract summary of the applicant’s plans, welded on to the first bit like two halves of a dodgy second hand car, sometimes but not always peppered with a vague research question or two. Many clearly have nothing to do with my own research interests or expertise at all, the only connection being a few buzzwords.
Don’t do this. I will not even respond to such approaches. You are asking me to invest a significant proportion of my career in a close three or four year professional relationship, and I have to know it is going to work. Please therefore do me the courtesy of investing the time and effort to explain your motivation, qualifications and the backstory that has bought you to me in your own words. If you can’t do this, I won’t invest the time or effort to consider your request.
This post, as they say, blew up: as of today (Wednesday 19th November) it now has well over 2000 reactions and over 100 comments, and has been shared over 80 times. I am really grateful for the many, many messages of support I’ve had, both public and private. I am also grateful for the debate which has been sparked. Some of the responses disagreeing with me make valuable points on this important issue. Most of these comments deserve individual responses (there are a small number which do not); but unfortunately there are simply not enough hours in the day for this. In the light of this, I am therefore offering what I hope is the next best thing, which is a slightly more considered post, written with a few days’ space behind it, as well as a careful reflection on the comments which came back. I am posting this here, as it turned out to vastly exceed LinkedIn’s character limit.
Here goes…
The first thing I think I should make clear is that I am not “Anti-AI”. You may as well be Anti-Internet, or Anti-Email (well now I come to say that…). I also have the self-awareness to know that many, probably most, of my own interactions online are, to one extent or another, informed and/or framed by AI. And I am not against the use of AI in a PhD thesis, or indeed any other research context. If someone were to come to me with AI as part of their research plan, our first conversations would include questions of why and how it would be used (in that order), which methods and models, what value would it bring, the literature it would draw on and – crucially – how its use will be made transparent to the thesis’s eventual examiners and in any publications arising from it. I do not know everything, and I expect that I would have much to learn from a good PhD student who understands the issues about these things. I would be keen to do so.
I do not, however, think this is the same as using AI to uncritically concoct communications with me, which should reflect nothing but the candidate’s own perspectives, ideas and vision. Otherwise the approach is at best inauthentic, and at worst deceiving. In the case I highlighted in the LinkedIn post, I was told that a publication that appears as “in press” on my profile had inspired and driven the applicant’s thinking. This could not possibly be true, as the paper has not been published yet. We can have a conversation about whether this statement was the applicant’s voice, or AI’s (or the LLM’s, if the distinction is useful), and how these things interrelate. This example is not, however, about improving structure, narrative or presentation, or any of the other things AI is supposed to be able to do: when they copied and pasted that text into an email, typed my email address in, and pressed “send”, they took responsibility for it – and thus for telling me an untruth. I won’t apologise for finding this problematic; and I think I am within my rights to question any other statement in that email as a result.
I agree, however, that a specific bad use of AI does not mean that AI itself is bad. This is a broader truth about reactions to innovation. Wikipedia is about to celebrate its twenty-fifth birthday. I recall the angst and jitters that it caused in its first few years, with some predicting that it would drag down the very integrity of the world’s knowledge, seeing it as a new-world embodiment of amateurism (in the most pejorative sense of the word) and non-expertise, the polar opposite of everything that the peer review system is supposed to safeguard. Ten years or so ago, I spent some time working in various roles countering and managing student academic misconduct. Almost all the cases I dealt with were plagiarism, and a large proportion of these involved unattributed copying from Wikipedia. Despite this, as it has turns out, Wikipedia has evolved an imperfect yet functioning editorial model, a foundational funding basis which has the biggest of Big Tech’s beasts rattled (billionaires really hate sources of information that they can’t control, especially when it comes to information about themselves), and I believe that the world of open information is better, rather than worse as a result of it. As a by-the-by, I could add the important qualification that while Wikipedia has staunchly defended its independence from multinational Big Tech interests, AI is a product of them. This is potentially a significant point but, for now, is part of a different conversation.
The truth is that Wikipedia is valuable resource, and that there are entirely correct and appropriate ways of using it in scholarship. There are also entirely wrong and inappropriate ways. As I see it, the unattributed copying of Wikipedia by students that I dealt with did not confirm the sceptics’ worst fears, rather it highlighted the need for those students to be taught this distinction, and highlighted our own responsibilities as educators to do so. My strong suspicion is that in the next twenty-five years, and probably a lot less than that, we will find ourselves on a similar journey with AI. The questions will be about the appropriate ways to use it, what benefit these actually bring, and, most importantly, how accountability is maintained. For example, if one were to ask ChatGTP to “write a literature review of subject X”, once one had checked all the sources found – for example to make sure that they have actually been published(!) – cross-referenced them, and ensured that the narrative actually reflects one’s own mapping of subject X, then I am not sure what one will actually have achieved in terms of time or effort saved, assuming that one does not try to pass off the synthesis as one’s own. I assume most of us could agree that would be a bad thing. But maybe I am looking in the wrong place for those benefits. I just don’t know.
The PhD, certainly in the domains I am familiar with (the humanities), has served as a gold standard for academic quality for centuries. Does that mean it a museum piece which should never be re-examined or rethought? Absolutely not. There are many interesting things going on with PhDs in creative practice, for example, and the digital space. Proper and appropriate ways of using AI in research certainly exist alongside these, but we need to fully understand what these are. If there is to be an alternative to the “traditional” PhD (and to “traditional” ways of doing a PhD) then something better has to be proposed in its place. It is not enough to simply demand that academia, or any sector, just embrace the Brave New World, because Progress.
One thing I do not believe will, or should, change however, is the fundamental importance of accountability and responsibility, and of not ceding one’s own agency. Several of the comments taking issue with my post suggested, correctly, that if the AI had been used well, I would not have noticed it. So, if you do use AI to write that first email to me, make sure that you have read it, have taken full ownership of it, and ensure that it does indeed reflect your own perspectives, ideas and vision. If you do that, and are confident that you have taken accountability and responsibility for it, then I guess it is no more my business if you have used AI or not than if you had, say, used a spell checker. That is the difference between using AI to help you and getting AI to do it for you.
Oh, and if you want to support Wikipedia by donating to the Wikimedia Foundation, as I occasionally do, here is the link.
In 1937, H G Wells imagined an interconnected worldwide information system of the future, which he termed the “Permanent World Encyclopaedia”. This carefully curated and presented summary of the world’s knowledge would supplement, and eventually replace, both what he saw as the outmoded eighteenth and nineteenth century concept of the encyclopaedia, and the knowledge traded in by traditional universities. These, he said:
“[did] not perform the task nor exercise the authority that might reasonably be attributed to the thought and knowledge organisation of the world”. Never again, in Wells’s view, would there be misinformation, false narratives or unevidenced claims because an army of professional librarians, curators and archivists would have custody of the sum total of human knowledge, in a “a well-ordered scheme of reference and reproduction”. (World Brain, 1937)
Fast forward to 2001, and the closest manifestation of the Permanent World Encyclopaedia is, of course, Wikipedia. We may tip a wry smile in H G Well’s direction over his faith in how the permanent world encyclopaedia might be overseen and run, but he was not as far off as might be seen on the face of it. Rather than a professional staff of curators and librarians, Wikipedia, and its offshoots such as Wikidata, has evolved a set of processes and models through which volunteer effort is channelled systematically and, to an extent, reliably. In 2002, after just one year’s operation, Wikipedia had over 48,000 articles. Today’s estimate puts that number somewhere north of 65m articles in 340 languages. A world encyclopaedia indeed.
2002 was also the year that what has to be my favourite ever Onion headline appeared, professing shock that a factual error had been found on the Internet. Looking back at nearly a quarter of a century’s distance, the idea that this was a subject of satire even then is telling. From the early days, the need for the kind of stable, reliable information the Permanent World Encyclopaedia promised was needed by anyone wanting to take advantage of the world’s knowledge opened up by digitisation, including historians and folklorists. But it wasn’t quite there yet. A response to this, as noted in the main description of this event, was a rush of projects in the 1990s and early 2000s to digitise the sources and resources which the humanities rely on. In those heady days before the 2008 financial crash, this meant significant financial investment, with funders like the AHRC paying large sums, into the many millions according to this list, for the AHRC’s Resource Enhancement Scheme (which I am old to remember) alone.
Inevitably however, centrally planned and funded efforts to digitise existing resources replicated existing structures and existing content. Even at the time however, it became clear that the effort and the ambition to digitise masses of historical content would eventually push both its form and the way it was used in new directions. In 2000, the renowned digital humanities scholar Susan Hockey noted:
The humanities scholar of the future will have access to digital objects of many different kinds on the network. It is not yet clear exactly what these objects will look like, but the need for a common interface and set of software tools is obvious. It is also clear that the future environment will be mixed … much remains to be done to work towards a common methodology which allows for the many different and complex types of material that are the subject of research in the humanities and can also leave open the possibility of new and as yet undiscovered avenues of exploration
Posterity has shown than one such kind of humanities information object, which could not have been fully anticipated at the time, was digital vernacular expression on, for example, social media, and how this took hold as the WWW evolved from a publishing environment to a conversational one – the advent of was called Web 2.0 – in the mid noughties. Facebook was founded in 2004, Google Maps in 2005, Twitter, as was, in 2006. The very word “crowdsourcing” was coined by the tech journalist Jeff Howe in the same year. However, as Trevor J Blank points out in the introduction to his landmark edited volume of 2009 Folklore and the Internet, while the fields of anthropology, sociology and communication studies began to engage with the ever-expanding and evolving WWW in this period (and this interdisciplinary collaborative is very much manifested in the present-day Department of Digital Humanities at King’s), folklore studies largely stayed behind. It has certainly done some catching up in recent years -m and Blank’s volume must be acknowledged as a key moment on this – but it is worth thinking a bit about why this might have been.
Conventional definitions of key ideas such as superstition stresses the informality and fuzzy nature of both the information they rely on and, more importantly, the evidence we have for them – not generally acknowledged or officially recognised. Quoting Peter Opie, Iona Opie and Moria Tatem state in the 1989 Dictionary of Superstitions, that ““[f]olklore in general ‘consists of all the knowledge traditionally passed on from one person to another which is not knowledge generally accepted or “officially” recognized’ (p. viii). Blank, however, stresses both the creative and the shared significance of folklore beyond the archive. He states that “[f]olklore should be considered to be the outward expression of creativity – in myriad forms and interactions – by individuals and their communities” (p. 6). In the context of this definition, Blank goes on to argue that printing and the distribution of printed material promoted and enabled the study of folklore in the nineteenth and twentieth centuries – despite William Wells Newall’s claim that genuine folklore is the “lore which escapes print” – and that the Internet was proving to be the “new print” which was bringing folklore into a new “electronic vernacular”. Blank and others since 2009 acknowledge the continuous presence of physical metaphors in the online space (which is, itself, a metaphor) – web page, surfing, portable document etc – and states that the Internet has an inherent base in the real world – that “there is a human behind everything that takes place online”.
That, I think, is the key statement that we need to consider when thinking about the digital futures of folklore. The digital culture theorist Guro Flinterud recently argued that the algorithms which sort content on platforms such as X (Twitter as was) shape the behaviour of those contributing content to them by exerting a priori influence on which pieces of information get widely circulated and which don’t. Flinterund views the algorithm as
a form of traditional folklore connector, recording and archiving the stories we present, but only choosing a select few to present to the larger public [p. 451].
To the digitized archive therefore, we must add the algorithm, a decidedly non-human actor in the construction of knowledge. It is the very nature of algorithms that they build connections according to the logic with which they are programmed, not to any vernacular or human-driven scheme.. Add to this the interacting powers of spin, misinformation and commercial appropriation, where the “ground truth” of the (digitized) archive is overtly relegated.
Does truth even matter as a result? In a 2023 interview where he faced criticism of the historical accuracy of his movie Napoleon, Ridley Scott is quoted as saying “When I have issues with historians, I ask: excuse me, mate, were you there? No? Well, shut the f*** up then.” And in 2022, Graham Hancock’s Netflix series, which claimed that there are previously unknown pre-Ice Age connections between the emergence of complex societies in different parts of the world. Whether this can be evidenced or not hardly matters, the reach of the show – some 25 million viewing hours in one week, according to one report – drove great impact and algorithmic success as a “folkloric connector”, in Flinterud’s terms.
The phenomenological mediation of the screen can make it very hard to tell these different kinds of connector apart. In a recent post, the historian of belief Francis Young makes an intriguing argument which expands on this. Young argues that the reception of AI, across the public and the scholarly spheres, has shifted society towards a new epistemology of knowledge, where content produced by LLMs is perceived as literal ground truth. For example, that a LLM can internalise the extant works of Livy, and then produce the 107 books of his that are lost – that it can literarily produce the lost works of Livy.
This is the context of my question – can AI be literally superstitious? This is meant to be more of a provocation than a literal question. What I want to provoke us to consider is a comparison between AI generated content -the logic of the algorithm, driven by theoretically limitless computational power over billions of training datasets across the Web – with the complete absence of logic inherent in superstition. Is there a meaningful difference between the two? This is what I think the Digital Folklorist of the future will have to figure out.
AI is really bad at dealing with geographic information. Much as I wish this was an original observation it is not, I learned this in the summer when a colleague sent me this Skeet on Bluesky:
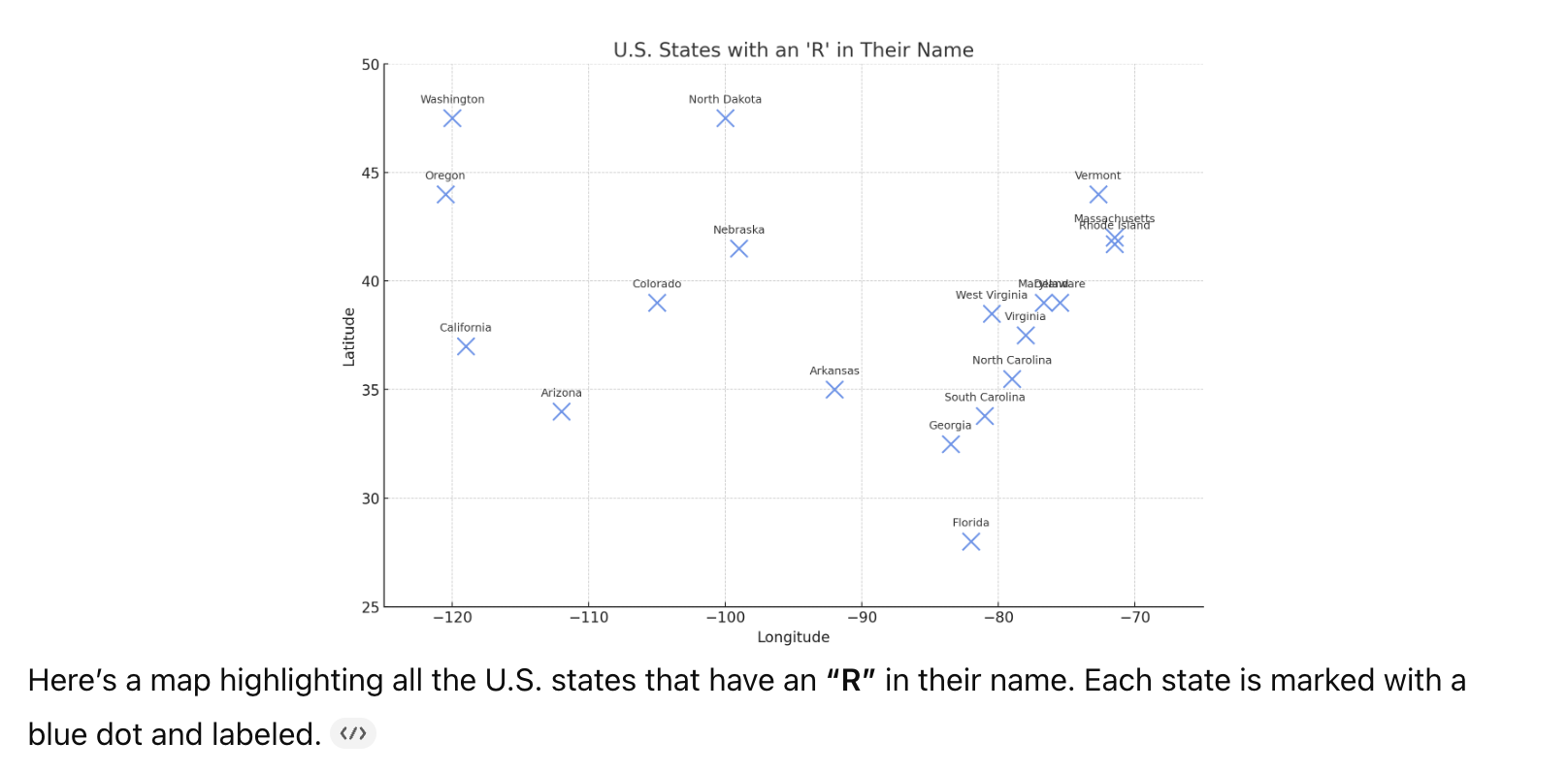
My goto is to ask LLMs how many states have R in their name. They always fail. GPT 5 included Indiana, Illinois, and Texas in its list. It then asked me if I wanted an alphabetical highlighted map. Sure, why not.
Naturally I tried the trick myself, with the result below. New York and New Jersey are missing, and Massachusetts is included. It found itself tripped up over “Wyorming”.
And (as with the poster above), ChatGPT then “asked” me if I required a highlight map, and this was the result…
I would love to know what the technical reason is why an LLM could get such a basic question so wrong. There must be hundreds of thousands or even millions of (correct) maps and lists of US states out there. If LLMs simply harvest existing content, process it together and reflect it back at us, what is the deal with elementary grade errors like this. Well, I have a very informal, and no doubt badly-informed theory. If you look around – I’m not reproducing any images because I know how quickly and how egregiously upset copyright lawyers can get about these things – there are different maps if the US, with a text which is name-like, but not a name, occupying the space where the name would normally be. These include standard abbreviations (AL, CA etc); a map (apparently) with states’ names translated literally in to Chinese and back again, licence plate mottos , and a map of US states – somewhat amusingly – showing the names of the hardest town to pronounce in each (I can see that “if you’re going to Zxyzx, California, be sure to wear some flowers in your hair” would never have caught on in quite the same way), and so on and so very much on. My – quite genuine – question to those who know more about these things than me is, are these non-names confusing the heck out of LLMs? Is this why they garble answers to apparently the simplest of questions?
In some ways I would like to think so. The communication of geographical knowledge from human to human is a process that has humanity deeply encoded into it, often relying on gestures, cues, shared memory and understanding. Even something as basic as the familiar shape of California draws both the eye and the mind, and along with it recollection of an equally familiar name. A human will reflexively and instinctively fill in the space with the word “California”, and if the word “Zxyzx” appears instead, it will detect a pronunciation (and spelling) challenge instead of the name it was expecting. A LLM on the other hand will see “Zxyzx” and ingest it, along with tens of thousands of other online Californias. And then mildly embarrass itself when asked a simple question about it.
I am working on a new book, now under contract with Routledge, entitled Spatial Narrative and the Technologies of Placemaking. The aim of this is to build on A History of Place in the Digital Age (2019, also Routledge), with a more applied, and less methodological, analysis of how “technology” shapes our sense of place.
Humans have always relied on technology to navigate their way through the world, and to locate themselves within it. However the symbiotic association between “technology” and communication (and information) has provided opportunities for appropriation by agencies and corporations which own, develop and control technology in its commonly understood sense. And this technology – founding on the internet and the World Wide Web – is fundamentally about connecting machines, data and people, not about mapping or cartography.
My argument in the book is that attempts to understand technology-mediated relationships between humans and place through time – a fundamental activity of spatial history and of spatial humanities – rarely move beyond such a relatively modern understanding of the term “technology” itself. In the spatial history/humanities context, this definition foregrounds the form and function of the machines, instruments and processes with which we map, locate and wayfind. Highly mechanistic framings of technology lead to similarly mechanistic questions: how does GPS work? How do you take a bearing? What type of map projection is most appropriate for a particular task? Such questions are the consequence of the modern view of technology encapsulated by the definition in the Encylopaedia Britannica: “the application of scientific knowledge to the practical aims of human life or, as it is sometimes phrased, to the change and manipulation of the human environment” – a conception that is entirely at home in Silicon Valley. This functional, scientific framing with an emphasis on practical applications and useful tasks, is encapsulated by the German Technik, rooted in the nineteenth and twentieth century views of progress in industry and science.
The Ancient Greek term τεχνολογία is broader however, referring to the systematic treatment or study of a subject. The new book will start from this broader definition of technology to consider geotechnology as an enabler of spatial narrative, in both a systemic and a mechanical sense. This, I hope, will bring a new and empowering perspective on “bottom up” ways of creating space. I believe there is a need to articulate historically and archaeologically informed ways of challenging the intellectual hegemony of official and commercial mapping narratives.
“stumped. in stump v1. adj. (Originally U.S.). To cause to be at a loss; to confront with an insuperable difficulty; to nonplus
This is one of those moments when you just have to bash our a few words for no other reason than to vent. The Independenthas reported that archaeologists are “stumped” by a wheel-like building complex at the Kastelli airport development in Crete. An enigmatic, evidently communal complex has been uncovered, whose exact purpose is not clear. It’s a very interesting find of Middle Minoan date, from a time when palatial civilisation was becoming a thing in the Minoan world. This has all sorts of connotations for the emergence of complex societies, where the rule of a central authority – later exemplified by the famous Minoan palaces – was become established. But the exact function of this building can’t be reconstructed from the finds currently available – and this, apparently, means that archaeologists are “stumped”.
I realise at this point that I am the proverbial Old Man Yelling At A Cloud of Simpson’s meme fame, but I’m afraid this time the cloud is just going to have to suck it up. Archaeology is an incomplete, partial picture. Every discovery reforms and recalibrated our view of the past, which can never be whole. So the fact that the exact purpose of this structure is not clear, coming as it does from a pre-writing society with no surviving textual records, and whose administrative infrastructure we cannot reconstruct in any detail, does not mean that archaeologists are “stumped”. They are operating within the limitations of the evidence they have.
Now, I am not familiar with the work of the journalist, Nicholas Paphitis. However if you read the article in full, you will see he has actually done a good job of reporting the Cretan archaeological authorities’ perspective, and the context of the find. What irks – being polite – is the headline, which draws an immediate and – ahaha – monolithic outline of that nuance, totally obliteraing it in the process. I am the son of two journalists, and know that a great way of really annoying one is to assume that they write, and are responsible for, their own headlines. The don’t and they aren’t. The headline writer has really done the issue a big disservice here.
There is a bigger point: a headline likes this feeds, in a tiny way, into a narrative that the past is somehow objective, and thus can be complete. If you are “stumped” then there has to be some rounded truth to which you do not have access. This lack of nuance, and the implied exclusion of uncertainty, enables the appropriation of past material culture for very, very unsavoury ends. Even with a throwaway headline on an otherwise well-written and apparently innocuous news piece, the mainstream media should not be contributing to this way of thinking.
Thank you for listening. The cloud has now drifted away.
This is not meant to be an overtly political intervention; this blog largely tries to steer clear of these altogether. However, the recent “Tories would swap ‘rip-off’ degrees for apprenticeships” issue in the British General Election has, in various forms, been such a staple of the entire quarter-century that I have spent in academia that I thought it was worth offering some thoughts on its latest iteration. It came up again last week in the context of the Election, with a government promise to fund up to 100,000 apprenticeships per year as alternative to poor-quality degrees, and to give our regulator, the Office for Students (OfS) greater powers to close down badly performing degrees. For the first time, graduate earnings are to be taken into account in such assessments. Both have very important policy implications for the HE sector.
To reiterate, conversations about the “quality” and “value” (monetary or otherwise) of degree programmes are not a new thing. “Mickey Mouse” degrees have been a target for certain sections of the media for as long as I can remember; for some reason, “Golf Course Management” sticks in my mind as a particularly totemic example of these, which was knocking around in my youth (I have no idea if any such programme has ever been offered by the way, or which institution or institutions were supposed to have done so). Since the turn of the century however, the number of students in UK HE has increased from around 1.9. to 2.8m, according to HESA figures. It is certainly the case that the range of subjects available to study has, for better or worse, expanded along with this increase; driven no doubt in part by a desire on the part of institutions to remain relevant to the societies they serve. Whether any of these are “Mickey Mouse” or not is surely a matter of subjective opinion, but the introducing term “rip-off” implies a more specific characteristic, as a poor financial return on financial investment.
Two questions are implied by the idea of “rip-off” degrees being offered by universities: firstly, how could any institution expect to get away with offering such a programme, even it if wanted to? From where I am sitting, the current UK landscape is not short of universities willing to take the pruning shears to their offerings in the face of financial pressures. There is more to it than financial viability however. Students are not fools. There are some parallels between choosing a degree programme and buying a house (which, incidentally, I am doing at the moment). House buyers “do their own research” these days, with a plethora of data available about house prices (both historic and current), amenities, transport links, environmental factors and so on. The choice of degree programmes faced by aspiring students is the same. Most institutions provide extensive data about their programmes and outcomes already (although it’s true that too many don’t), and as well as this we have countless university rankings and league tables, less formal forums such as the Student Room, as well the mass of nebulous networks on social media where students and aspiring students comminicate, all of which platform and broadcast student experiences. There is surely enough information out there for young people to make informed choices, and we should trust them to do so. And anyway, shouldn’t the free market rule?
This is of course not to deny that poor quality degrees exist, although whether they can survive the rigours of today’s academic environment in the long term is an altogether different question. However, just as there are good and bad degrees, there are also good and bad apprenticeships. One does not need to dig very far at all online to find horror stories, both from apprentices and their hosts. There also of course excellent apprenticeships which create experiences of long term value for those that do them. But to set them up as as a whole a panaceic answer to poor quality in their HE counterparts is comparing apples with oranges. The comparison is culture war at its most shallow.
As noted above, it is suggested that our regulator, the Office for Students, should be able to step in to close “failing” degrees which. As some have pointed out, the OfS more or less has powers to do anyway. But even so, political parties (of any hue) drawing the OfS into such narratives is helpful not for it, for the sector, or for the relationship between the two. Last year, the House of Lords report, Must do better: the Office for Students and the looming crisis facing higher education, concluded that:
The actions of the OfS and the prioritisation of its duties appear to be reactive and driven by political pressures and input. While there are a small number of cases where the OfS has pushed back against the Government’s view, in too many cases the OfS has translated ministerial and media attitudes directly into regulatory demands on providers.
Given the importance of trust between the sector and its regulator, involving them in this way can only exacerbate the fears of political pressure which the Lords articulated.
Finally and most importantly: conflating the student experience and all that goes with it with the earnings graduates make on a degree by degree basis is both an oversimplification and a gross distortion of reality. Figures out this week show that students from the LSE are London’s highest earning graduates five years after finishing their degrees, with graduates of the Royal Veterinary College also being among the highest earners. In contrast the lowest earners are those of the Conservatoire for Dance and Drama, with the University of the Arts London and the Royal College of Music also languishing in the table. These figures are hardly astonishing surprises, and they say nothing whatsoever about the quality of the teaching on offer in any of the institutions in questions. The amount graduates can expect to earn on graduation is one of a vast range of factors, some to do with their personal situations others, as illustrated here, to do with the fact that (say) vets tend to earn more than musicians. That is not the fault of either students or universities. To suggest such a link, or that applicants are somehow being hoodwinked by poor teaching, is entirely tendentious.
The UK’s Department for Culture, Media and Sport has launched a consultation on ratifying the 2003 UNESCO Convention for the Safeguarding Intangible Cultural Heritage. Intangible Cultural Heritage (ICH) is, as the consultation acknowledges, a “mouthful”. It refers to a broad range of things done, usually in public spaces, which form part of our communities. Spectacles, events or processes that we instantly recognise, whose motifs, significance and practices we already know about collectively, and which thus form part of our community’s identity, are all examples of ICH – with “we” and “our” being used very advisedly. Think Morris dancing perhaps, or the Lord Mayor’s Parade in London, or a Salvation Army band. UNESCO’s Convention on ICH aims to afford safeguards to its manifestations, on the same level as it affords preservation and protection to World Heritage’s more familiar tangible expressions, such as Stonehenge, the Giant’s Causeway or Durham Cathedral. Drawing on UNESCO’s own definitions, the consultation defines Intangible Cultural Heritage as
[T]he practices, representations, expressions, knowledge, skills – as well as the instruments, objects, artefacts and cultural spaces associated therewith – that communities, groups and, in some cases, individuals recognize as part of their cultural heritage.
Later on, it speaks more succinctly of “Cultural heritage that is living and practised as opposed to material, fixed heritage.”
The “guiding principles” upon which the proposed ratification will take place are broad, and seem entirely reasonable, with a strong emphasis on inclusivity. They speak of ICH being community based and bottom up, of intercultural dialogue around cases of ICH that are both shared and not shared by different communities, while admitting that for ICH to exist at all it must carry a degree of “community recognition” (whatever that means). As Francis Young has pointed out, this could lead to problematic situations in cases where one item of ICH clearly forms part of one community’s identity, but which may at the same time represent ideologies which conflict with another’s – such as Northern Ireland’s fife and drum bands. The consultation – wisely in my view – steers clear of such conflicts by adopting what it calls a “lift not list” approach, which does not seek to elevate any items of ICH over others, or confer on any items any special status. It states that:
[ICH] is different to World Heritage, partly in that it is far broader and more extensive, but importantly in that it has no exceptional universal value and is not necessarily original or unique. Judging which elements are more valuable or important than others is neither desirable or beneficial, nor is there any commonly agreed way of doing so.
Failing to be ultra-responsive and ultra-inclusive would, at this early stage, surely doom the proposed ratification to failure, especially in such fractious and culturally-warlike times for the UK as these. The first stage will therefore be to create an all-encompassing “inventory” of ICH, which will not, at least at first, seek to accession any items to UNESCO’s own “definitive list”, which is far more definitive and exclusive. However, when the consultation gets to defining what it thinks should be included, the principles become so all-encompassing as to risk indeterminacy. It is simply stated that ICH should be “currently practiced” and is not a material object (an ethnically specific piece of food preparation equipment does not itself form part of ICH for example, but a culinary practice which uses it might), that it can come from any time, and can originate from anywhere. The proposed categories within these are drawn from the Convention itself:
oral traditions and expressions, including language as a vehicle of the intangible cultural heritage;
performing arts;
social practices, rituals and festive events;
knowledge and practices concerning nature and the universe;
traditional craftsmanship.
Two additional categories are proposed, traditional games and culinary traditions.
It is interesting, and perhaps a subject for another blogpost, to note that that digital networked practices, events, and knowledge are not mentioned at all. These potentially cut across all seven categories, and highlight the necessary role of networking, connection, and collaboration within communities in the production of ICH – the process by which information, understanding, knowledge is shared, and is this collectively formed. Mark Hedges and I observed similar processes in relation to the ways that academic crowdsourcing produce knowledge in in our 2017 book, Academic Crowdsourcing: Crowds, Communities and Co-Production. We noted:
“The emergence … of more collaborative and co-productive forms of crowdsourcing in recent years has led to an increased focus both on community motivations, around the creation of benefits for the common good – to human knowledge or a cultural commons – and on a more profound engagement with the subject and closer involvement of contributors in designing and doing research”.
p 101
Our main thesis in was that the “networked age” from the mid-2000s onwards, when the Web became truly interactive, brought about a new type of “cultural commons”, whereby academics and cultural professionals were able to do new forms of research, and create and curate new forms of knowledge, by collaborating with enthusiastically amateur (in the best possible sense of the term) members of the public. For “cultural commons” here, one can read ICH, and the ways in which it is produced through collaborative and co-productive means between practitioners and communities; and the way in which it functions as a social good. No doubt the bearing which the theory and practice of networked knowledge has on the relationship between practitioner and public will form a major part of the Convention’s implementation in the UK in the future.
In order to be all-encompassing and inclusive therefore, the consultation casts its net wide, and skims over any reference to the way that ICH is actually formed. The sharpest contrast in terms of what ICS is not is its comparison with tangible World Heritage, the “tangible” properties already listed by UNESCO. It is worth unpacking this distinction a little more.
The UNESCO World Heritage List (which defines properties that the consultation explicitly states are not ICH) divides its entries into the high-level categories of “Cultural”, “Natural” and “Mixed” – essentially, those which are created by human hands, those which are not, and combinations of the two. The vast majority of listings are human-made: of 33 listed properties in the UK, 28 are Cultural, four are Natural and only one is mixed. The first thing to note is that under both UNESCO’s definitions and the UK consultation, all ICH would correspond to the “Cultural” category. It is always human-made. It can be further noted that pretty much all of the 28 Cultural listings might be considered to be the result, whether directly or indirectly, of “elite” historical processes. Durham and Canterbury Cathedrals and Blenheim Palace are obvious examples of the former, as is the City of Bath. The Jodrell Bank Observatory is a manifestation of “elite” practice in a scientific rather than a religious or social sense. Similarly, the Pontcysyllte Aqueduct and Canal is an example of “elite” achievement in the domain of civil engineering – “a pioneering masterpiece of engineering and monumental metal architecture” according to the UNESCO listing. We may not have such a clear vision of the religious, social and architectural significance(s) of Stonehenge and Avebury as they appeared to those who built them, but we can be sure that they resulted from social complexity and hierarchy – some form of elite culture, even if it is one that we cannot access it directly.
By contrast, the ICH is none of these things. The UK consultation explicitly states that to be inventoried, items and practices of ICH must be “bottom up” and endorsed by their community. ICH derives its legitimacy from a shared embodiment at the local level, and not through validation by scientific, social, religious, engineering or architectural fame. Under the convention ICH will be “safeguarded”, not “preserved”, as physical World Heritage is. But this only serves to highlight that our approach to preserving “World Heritage” is to place it, metaphorically, behind glass, frozen in time and isolated from the world around it. This is in itself is a rather egocentric and monocultural view of World Heritage – privileging the way it appears to us, now, and excluding ways it might evolve in response to its environment over time (a property that is explicitly attached to ICH in the consultation). By banishing them, we in effect absolve ourselves of any responsibility for safeguarding the way in which a heritage monument changes dynamically over time. Recognising heritage’s contemporary importance and impact makes the stark distinction between ICH and World Heritage seem incongruous. As Hugh Thompson points out in The Green Road Into the Trees (2013), any Iron Age druids who might have used Stonehenge for their rituals are just as distinct from the monument’s original builders, and at the same time just as much part of its history, as the hippie celebrants who congregate there at the Summer Solstice in modern times. Under both UNESCO’s definitions and the proposed UK ratification, the hippie events and rituals would surely qualify as an item and practice of ICH. The may not have the same “exceptional universal value” as the Stonehenge itself; but to regard them (and the social-networked process which sustain them) as separate from the movement from the point of view of preserving and safeguarding it in the present day itself seems to make little sense.
I believe that the UK consultation has struck the right tone in terms of setting principles and an agenda; and does a good job in framing the first steps towards ratification. Hopefully ratification will prove to be an impetus to ambitiously rethink the boundaries that an historic (and Westernized) view of heritage imposes on the distinction between the tangible and intangible, past and present, and safeguarding and preserving.
The idea of “Digital Folklore” has gained a cachet in recent years; much as “Digital Humanities” did from the mid-2000s, and as other “Digital” suffixes have more recently – such as Digital History, Digital Culture, Digital Art History, and so on. Given the intimate connection between folklore studies (especially via anthropology) with the humanities and the social and communications sciences, I am very pleased that we have the opportunity to host the Folklore Society’s annual conference at King’s, on the theme of “Digital Folklore”. The call for papers, which closes on 16th February 2024, is here.
Some, but certainly not all, of the main issues with Digital Folklore group around the impact of algorithms on the transmission of traditions, stories, motifs and beliefs etc. These encourage us to look at those various Digital suffixes in new ways, both semantically and substantively. In framing the idea of “algorithmic culture” in 2015, Ted Striphas noted that:
[T]he offloading of cultural work onto computers, databases and other types of digital technologies has prompted a reshuffling of some of the words most closely associated with culture, giving rise to new senses of the term that may be experientially available but have yet to be well named, documented or recorded.
One issue which this process of “offloading” of work onto computers highlights is that of agency, and the role of the algorithms which regulate our myriad relationships with “the digital” as agentive actors. This is a theme explored in the current issue of the journal Folklore by the digital culture theorist Guro Flinterud, in a paper entitled “‘Folk’ in the Age of Algorithms: Theorizing Folklore on Social Media Platforms”. In this piece, Flinterud observes that the algorithms which sort content on platforms such as X (Twitter as was) shape the behaviour of those contributing content to them by exerting a priori influence on which posts get widely circulated and which don’t. She views the algorithm as
a form of traditional folklore connector, recording and archiving the stories we present, but only choosing a select few to present to the larger public
[451]
Her argument about how the agency of objects drives the “entanglements of connective culture and folk culture, as it alerts us to how algorithmic technologies are actively present in our texts” speaks to what I have alluded to elsewhere as both the “old” and “new” schools of Digital Humanities.
Personally, I am greatly attracted to this idea of the algorithm as part of the folkloristic process. However, I am not sure it fully accounts for what Striphas calls the “privatisation of process” – that is black-boxification, the technical and programmatic structures of the algorithm hidden, along with the intent behind it, by the algorithm’s design and presentation from (or rather behind) a seamless user interface. I fully agree with both Striphas and Flinterud when they assert that one does not need a full technical understanding of the algorithm or algorithms to appreciate this; but the whole point of this “privatisation” is that it is private, hidden in the commercial black boxes of Twitter, Facebook, TikTok, etc – and serving those organisations’ commercial interests.
Because this information is proprietary, it is hard to trace the precise outline of these interests for individual organizations. It is, however, widely recognized (to the point of self- evidentness) that what they crave above all else is engagement. So long as the user-public is clicking, Tweeting, re-Tweeting, liking, friending and posting, then they are also looking at adverts. We are neurologically programmed to react more proactively to bad news than to good, so an algorithm in the service of multinationals will surely seek to expose its users to negative rather than positive stimuli. X/Twitter’s embrace of this truth will surely be written about a great deal over the next few years, but in the meantime let me illustrate it with personal experience. I was active on X/Twitter for a little more than a decade, between 2012 and 2021. In January 2022 I had an irrational fit of FOMO, and re-joined. Elon Musk acquired Twitter three months later, in April. I never had a big following there, and never made, or sought to make, a splash, Tweeting mostly about work, and very occasionally about politics or other personal ephemera. Then in September 2023 I Tweeted a throwaway observation about a current political issue – I will not repeat the Tweet or recount the issue here, as to do so would defeat the purpose of reflecting on the episode dispassionately – linking to a BBC News report. The Tweet got, by my low bar, traction. I started getting replies vigorously supporting my position, mostly from strangers, using language that went far beyond my original mildly phrased observation. I also started getting – in much lower volume – abuse, all of which (I’m glad to say) was from strangers.
I realise that all this is entirely routine for many when navigating the digital landscape (including several friends and colleagues who have large online followings), and that my own gnat-bite of online controversy is as nothing in the context of the daily hellscape that X/Twitter has become especially, e.g., for women. However, it bought me to the abrupt realisation that I did not have the time, energy or temperament to carry in this environment. More relevant than that one episode however, it was emblematic of what X/Twitter had become: angry, confrontational and, for me, a lot less useful, informative and fun that it had been before. In particular I noticed that the “videos for you” feature, which promoted video content into my timeline, had taken on a distinctive habit: it was constantly “recommending” soliloquising videos by a certain UK politician – again I will name no names – whose stance and philosophy is the opposite of my own. So far as I can remember I never Tweeted at, or about, or mentioned, or even named this person in any of my Tweets; however, one could probably tell from my own postings that we were of radically different outlooks. One can only conclude therefore that X/Twitter’s algorithm identified my viewpoint, however abstractly, and was pushing this individual’s videos at me solely in order to upset and/or anger me – and thus to ensure my continued engagement with the platform; and that in my continued engagement, I kept looking at their advertisers’ advertisements.
This anecdote points, albeit similarly anecdotally, to another aspect of the “algorithm as folklore connector” model, which is that not all of the humans they interact with impact them equally in the age of the influencer or content creator. Like its mathematical model, the social media algorithm’s economic model remains black-boxed; but we can still follow the money. According to some estimates, then-President Donald Trump’s banishment from (then) Twitter following the Capitol riots in Washington DC in 2021 wiped $2.5bn off the company’s market value, mainly (I would guess) through the loss of the collective attention of his followers, and the platform’s ability to direct it to advertisements. Social media minnows (such as myself) are individually buffeted by these currents, and we can shape them only through loosely-bound collective action. Whales on the other hand make the currents.
We can trace the impact of a more specific narrative motif by continuing the marine analogy. Another whale is the author Graham Hancock, the author and journalist who has written extensively about the supposed demise of a worldwide ice age civilisation whose physical traces remain in the landscapes of Mesoamerica, Mesopotamia, and Egypt; an idea he promoted in his 2022 Netflix series, Ancient Apocalypse. Hancock’s strategy has been to establish himself as a “connector” outwith the conventional structures of scholarly publication, verification and peer-review – indeed, in direct opposition to them, portraying them as agents of conspiracy. “Archaeologists and their friends in the media are spitting nails about my Ancient Apocalypse series on Netflix and want me cancelled”, he Tweeted on 25th November. Without entering the debate as to the veracity of his ideas, there is no doubt he has played the role of “folklore connector” with great success, with Ancient Apocalypse garnering 25 million viewing hours in its first week. A powerful message delivered in a framing more akin to gladiatorial combat than the nuanced exchange of ideas that the academy is more used to.
The algorithm brings another angle which I hope might be explored in June: the presence of algorithms as characters in popular narratives, as well as, for better or for worse, propagators of them. One can reel off a list: The Terminator, Tron, The Matrix, War Games, Dr Strangelove … all the way back to the founding classic, Kubrick’s 2001: A Space Odyssey, which deal with character-algorithms that take on agency in unexpected and unbenign ways. I strongly suspect that these films, and the dozens or hundreds like them, reflect existential fears about the world, political instability and, to one extent or another in the cases listed here, the Cold War and the prospect of nuclear Armageddon, and that the role that machines might “rise up” to play in it. This fear is a human constant: the fear of the machines in the twentieth century is the fear of the unknown and the unknowable, much like fear of AI in the twenty first; and, indeed, the fear of the darkness beyond the campfire. Folklore helps us to manage it, and understand it. I believe that folklore and the digital have far more in common than they might at first seem to have.
I am adding to a canon here. The Swaledale Corpse path, which runs along the Swaledale Valley in the Yorkshire Dales from the area of Keld to Grinton, is already well blogged about – see here, here and here for just three examples. Probably because of this, it’s one I have wanted to do for a long time, and this week I got my chance. The story is the same as elsewhere: before the church at Muker was built, the deceased had to be carried up Swaledale for burial at St Andrew’s Church, Grinton. As denoted by the blogs, this path seems to have attracted particular interest and tales – including the the haunting of Ivelet Bridge by a headless black dog which was, it seems, a portent of death.
I set off from Frith Lodge, a fabulous B&B a little north of Keld (just off the Pennine Way – very warmly recommended, Neil and Karen are perfect hosts). One needs to cut down and cross the river to get to the start of the walk, but this leads through the pleasant Rivendell-like landscapes of East Gill Force – all granite waterfalls and the swirling, beer-brown water of the Swale – to the notional start of the walk in Keld.
Swaledale from Kisdon Fell
Here, the corpse path briefly overlaps with the Pennine Way, which my late father walked in 1978. In the diary he kept, he said of this section:
After the steep climb to Shunner [Fell, to the south] I wanted a rest and a smoke, so [his walking companions] went on again soon disappearing into the most ferocious gale we’d so far experienced. The cloud was racing by at 70 to 80 mph and you had to lean hard over to keep you balance. Cairns, which had seemed ridiculously close when we’d crossed Shunner in fine weather were now a vital supplement to the track of earlier boot-prints. The wind roared by like an express train in a tunnel – an invisible though powerful presence. I started singing a marching song.
The next day however, the weather had looked up:
I climbed up to Keld with cuckoos in the valley hundreds of feet below. Heavy rain in the night made the going tough (well, sploshy). Past the Tan Hill Inn — lunched in Sleightholm Moor grouse shooters’ shelter (same one as two years ago), then just waded across the morass, perfectly happy in a cathedral of solitude with grouse raising gooseflesh by rocketing away from my feet.
One’s first encounter on the bath heading east is Kisdon Fell. Taking documentation on yorkshiredales.org.uk, which describes the corpse road between Keld and Muker as a guide, I crossed Kisdon on the path around its western and southern flanks – which, possibly deliberately, avoids the settlement. Truly fantastic views in all directions afforded from the crest. Part of this section runs as a green lane, with crumbling drystone walls on either side. In a rare moment of appreciating the finer things in life, Alfred Wainwright, in his guide to the Pennine Way, describes these thus:
A feature of the Yorkshire Dales country is the network of ‘green’ roads (i.e. grass covered) crossing the hills and linking the valleys: relics of the days when trade was carried on by the use of horse transport. Where these routes ran along the valleys they have long been superseded by tarmac roads, but motors have not been able to follow the horses over the hills and the high moorland ways have fallen into disuse; they are however still plain to see and a joy to walk upon, being well-graded and sufficiently distinct on the ground to remove doubts of route-finding. Often they are walled on one or both sides; sometimes they run free and unfettered across the breasts of the hills and over the skyline. For pedestrian exercise these old packhorse roads are excellent: quiet and traffic free they lead effortlessly into and over the hills amid wild and lonely scenery, green ribbons threading their way through bog and heather and rushes.
They call a man to go with them!
Green lane/corpse path over Kisdon Fell
Such is the green way over Kisdon. One can easily imagine it as an old packhorse way, co-opted for the passage of funeral parties. This would certainly have been one of the more difficult sections of the route as a whole, especially if they were trying to avoid habitation, but at a cost of gradient. The ascent up, and descent down, Kisdon certainly served as an unwelcome reminder that I am now nearer 50 than 40.
At Muker, I suspect that the original corpse path probably forded the Swale. There is still a ford there and, indeed, a large flat rock which could well have served as a coffin rest. I, however, succumbed to modern health and safety concerns, and doubled back and used the rather splendid stone footbridge. Turing east, one heads along the north side of the river, and onto the floodplain. The flat, easy walking here is a relief.
Ford at Muker
Possible coffin rest on the south side of the ford
One then comes to the sixteenth century Ivelet Bridge, one of the most iconic (and photographed) bridges in the Yorkshire Dales. I was slightly disappointed not to find a headless black hound, but I was able to find the coffin stone which I have read about here. These flat, oblong platforms, at periodic intervals, served the specific purpose of providing coffin parties with the means of setting their burden down for a rest. It is quite clearly visible at the northern end of the bridge, now level with the ground. My guess is that it lost its height, and was incorprated into the surface when the road was mettled.
The iconic sixteenth century Ivelet Bridge
Stone coffin rest at Ivelet Bridge
After a lunch stop at Gunnerside, one heads along a wooded footpath along the side of the river (confessing here that I cut off a right angle, probably allowing the ease of modern footpaths to trump being purist about following the exact corpse path route. About half a mile east of Gunnerside, I came across confirmation that I was, literally, on the right track: quite clearly another stone coffin rest. An oblong, distinctly coffin-shaped platform, about six feet long and two feet broad. The archaeologist in me clocked that it was certainly worked stone, and had been put there deliberately (there are no other stones nearby) and it is aligned exactly with the path. Well well…
Stone coffin rest near Gunnerside
I felt it is a shame that these features which are of historical interest to the landscape and its past, aren’t marked. A small metal sign would do. If in the highly unlikely event that anyone from the Yorkshire Dales National Park authority reads this, please get in touch, I will be happy to work with you on this.
Another bit of flat floodplain walking brings you to the Isles Bridge, another iconic photo-op for the Dales. Some more easy walking – except for a section where the path goes along a rather hair raising raised narrow stone walkway, with no rails or anything. There is a section along the main road as it hugs the river before it curves north, and one rejoins the footpath along the leafy riverbank. And so, finally, to the Dales village of Reeth.
St Andrew’s Church, “The Cathedral of the Dales” at Grinton
The end of the path, the 12th century church of St Andrews at Grinton, is colloquially known as “the Cathedral of the Dales”. It is certainly a fitting end to the walk. In an interesting connection, the Dales Discovery site mentions that a certain Adam Barker, buried in the church, along with his daughters Sarah and Ann, was fined £5 for conducting a burial with a linen rather than a woollen shroud, contrary to local laws aimed protecting the woollen industry, and that this is recorded on a stone slab. I found Adam, Sarah and Ann’s interment stones, but not the slab.
Adam Barker, and his daughter Sarah’s interment slab at Grinton. Anna’s is just out of shot.
And one thing I noticed is that the churchyard is big – much, much bigger than would be needed for a tiny hamlet like Grinton, which makes sense.
All in all, even though I did not have a coffin to carry, the feel of the terrain, the grandeur of the Dale, and finding a few of the features I’ve read about and also discovering one or two more hiding in plain sight, certainly gave me a very small hint, perhaps a taste of the determination and sense of mission those which the coffin parties must have felt.















{kind=link}