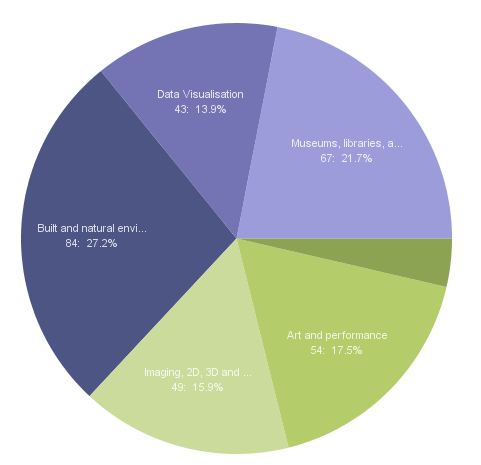
Last week, thanks to my Fellowship of the Software Sustainability Institute, I attended Electronic Visualization and the Arts in Florence. This fascinating and wide-ranging conference bought together a tremendous range of people and ideas. Strategy, application, theory. A fascinating take on crowd-sourcing appeared in the form of a project of ETH-Bibliotek in Zurich, cataloging a massive image archive of daily life working for Swissair using the knowledge of Swissair retirees.

Another issue that came up was the challenge associated with archiving a digital image for the very long term – 150 years or more? Today we still have images taken in the 1920s and 1930s, can digital imaging deliver similar longevity? The short answer is almost certainly not. One strategy discussed, by Graham Diprose and Mike Seabourne, is to archive digital artwork and photography by printing it on specially prepared paper; an approach they describe as a ‘technology proof form of insurance’. I think this raises important issues about how images, digital or otherwise, are dealt with as ‘objects’. This topic has a certain hinterland in the domain of cultural heritage, as the concept of the ‘object biography’ has been discussed since at least 1999, when Chris Gosden and Yvonne Marshall wrote that ‘as people and objects gather time, movement and change, they are constantly transformed, and these transformations of person and object are tied up with each other’ (‘The Cultural Biography of Objects’, World Archaeology, Volume 31 No. 2 [October 1999]: 169-178). The key difference with images – an susbset class of objects that has only existed for a little over one hundred years – subject, significance and material can be separated. What an image depicts is separate from the materiality of the photograph itself — and from the cloud of numbers that make up a digital image. Such considerations encourage us to think about what the ‘biography’ of an image might look like. And this is important. The Gosden-Marshall model of the object biography has gained currency in a number of major museums, including the Pitt Rivers. The implications of the image biography, where meaning and material are preserved side by side, will be preserved side by side, can only be done if the relationships between these two are also preserved. This will include methods for preserving metadata (a point made in the session by Nick Lambert); but it also accords, I think, with the broader intellectual direction of where visualization is going.

To explain this: this year, in London, EVA International will celebrate its 25th anniversary. In the last twenty five years, much digital visualization has been contingent of the presentation of 3D material on the 2D screen. My sense from the last three or so EVA Londons, confirmed by EVA Florence, is that in the next twenty five years, visualization will involve the 2D screen less and less. A greater proportion of demos at EVA London now involve objects, not screen-based presentations. Carol MacGillivray, Bruno Mathez and Frederic Fol Leymarie’s Diasynchonosope project in 2013 and Gary Priestnall, Jeremy Gardiner, Jake Durrant & James Goulding’s Projection Augmented Relief Models in 2012 are particularly striking examples, but there are many more. Preserving these visulaziations, including more conventional digital images, will require an integrated cloud of thinking on software sustainability, and its relationship to curation practice, digital augmentation and policy. I look forward to seeing more illustrations of this in London in July. I was also happy to participate in a network meeting of EVA international on the third day.The meeting ended with a small ceremony to inaugurate a plaque in the newly refurbished room to commemorate the event (see photo – this is a facsimile, pending the real thing being engraved).