The 18-month Institute in Digital Art History is led by King’s College London’s Department of Digital Humanities (DDH) and Department of Classics, in collaboration with HumLab at the University of Umeå, with grant support provided by the Getty Foundation as part of its Digital Art History initiative.
It will convene two international meetings where Members of the Institute will survey, analyse and debate the current state of digital art history, and map out its future research agenda. It will also design and develop a Proof of Concept (PoC) to help deliver this agenda. The source code for this PoC will be made available online, and will form the basis for further discussions, development of research questions and project proposals after the end of the programme.
To achieve these aims we will bring together leading experts in the field to offer a multi-vocal and interdisciplinary perspective on three areas of pressing concern to digital art history:
● Provenance, the meta-information about ancient art objects,
● Geographies, the paths those objects take through time and space, and
● Visualization, the methods used to render art objects and collections in visual media.
Current Digital Humanities (DH) research in this area has a strong focus on Linked Open Data (LOD), and so we will begin our exploration with a focus on LOD. This geographical emphasis on the art of the ancient Mediterranean world will be continued in the second meeting to be held in Athens. The Mediterranean has received much attention from both the Digital Classics and DH communities, and is thus rich in resources and content. The programme will, therefore, bring together two existing scholarly fields and seek to improve and facilitate dialogue between them.
We will assign Members to groups according to the three areas of focus above. These groups will be tasked with producing a detailed research specification, detailing the most important next steps for that part of the field, how current methods can best be employed to make them, and what new research questions the participants see emerging.
The meetings will follow a similar format, with initial participant presentations and introductions followed by collaborative programme development and design activities within the research groups, including scoping of relevant aspects of the PoC. This will be followed by further discussion and collaborative writing which will form the basis of the event’s report. Each day will conclude with a plenary feedback session, where participants will share and discuss short reports on their activities. All of the sessions will be filmed for archival and note-taking purposes, and professional facilitators will assist in the process at various points.
The scholarly outputs, along with the research specifications for the PoC, will provide tangible foci for a robust, vibrant and sustainable research network, comprising the Institute participants as a core, but extending across the emerging international and interdisciplinary landscape of digital art history. At the same time, the programme will provide participants with support and space for developing their own personal academic agendas and profiles. In particular, Members will be encouraged to and offered collegial support in developing publications, both single- and co-authored following their own research interests and those related to the Institute.
The Project Team
The core team comprises of Dr Stuart Dunn (DDH), Professor Graeme Earl(DDH) and Dr Will Wootton (Classics) at King’s College London, and Dr Anna Foka of HumLab, Umeå University.
They are supported by an Advisory Board consisting of international independent experts in the fields of art history, Digital Humanities and LOD. These are: Professor Tula Giannini (Chair; Pratt Institute, New York), Dr Gabriel Bodard (Institute of Classical Studies), Professor Barbara Borg (University of Exeter), Dr Arianna Ciula (King’s Digital Laboratory), Professor Donna Kurtz (University of Oxford), and Dr Michael Squire (King’s College London).
Call for participation
We are now pleased to invite applications to participate as Members in the programme. Applications are invited from art historians and professional curators who (or whose institutions) have a proven and established record in using digital methods, have already committed resources, or have a firm interest in developing their research agendas in art history, archaeology, museum studies, and LOD. You should also be prepared to contribute to the design of the PoC (e.g. providing data or tools, defining requirements), which will be developed in the timeframe of the project by experts at King’s Digital Lab.
Membership is open to advanced doctoral students (provided they can demonstrate close alignment of their thesis with the aims of the programme), Faculty members at any level in all relevant fields, and GLAM curation professionals.
Participation will primarily take the form of attending the Institute’s two meetings:
King’s College London: 3rd – 14th September 2018
Swedish Institute at Athens: 1st-12th April 2019
We anticipate offering up to eighteen places on the programme. All travel and accommodation expenses to London and Athens will be covered. Membership is dependent upon commitment to attend both events for the full duration.
Potential applicants are welcome to contact the programme director with any questions: stuart.dunn@kcl.ac.uk.
To apply, please submit a single A4 PDF document set out as follows. Please ensure your application includes your name, email address, institutional affiliation, and street address.
Applicant Statement (ONE page)
This should state what you would bring to the programme, the nature of your current work and involvement of digital art history, and what you believe you could gain as a Member of the Institute. There is no need to indicate which of the three areas you are most interested in (although you may if you wish); we will use your submission to create the groups, considering both complementary expertise and the ability for some members to act as translators between the three areas.
Applicant CV (TWO pages)
This section should provide a two-page CV, including your five most relevant publications (including digital resources if applicable).
Institutional support (ONE page)
We are keen for the ideas generated in the programme to be taken up and developed by the community after the period of funding has finished. Therefore, please use this section to provide answers to the following questions relating to your institution and its capacity:
1. Does your institution provide specialist Research Software Development or other IT support for DH/LOD projects?
2. Is there a specialist DH unit or centre?
3. Do you, or your institution, hold or host any relevant data collections, physical collections, or archives?
4. Does your institution have hardware capacity for developing digital projects (e.g. specialist scanning equipment), or digital infrastructure facilities?
5. How will you transfer knowledge, expertise, contacts and tools gained through your participation to your institution?
6. Will your institution a) be able to contribute to the programme in any way, or b) offer you any practical support in developing any research of your own which arises from the programme? If so, give details.
7. What metrics will you apply to evaluate the impact of the Ancient Itineraries programme a) on your own professional activities and b) on your institution?
Selection and timeline
All proposals will be reviewed by the Advisory Board, and members will be selected on the basis of their recommendations.
Please email the documents specified above as a single PDF document to stuart.dunn@kcl.ac.uk by Friday 1st June 2018, 16:00 (British Summer Time). We will be unable to consider any applications received after this. Please use the subject line “Ancient Itineraries” in your email.
Applicants will be notified of the outcomes on or before 19th June 2018.
Privacy statement
All data you submit with your application will be stored securely on King’s College London’s electronic systems. It will not be shared, except in strict confidence with Advisory Board members for the purposes of evaluation. Furthermore your name, contact details and country of residence will be shared, in similar confidence, with the Getty Foundation to ensure compliance with US law and any applicable US sanctions. Further information on KCL’s data protection and compliance policies may be found here: https://www.kcl.ac.uk/terms/privacy.aspx; and information on the Getty Foundation’s privacy policies may be found here: http://www.getty.edu/legal/privacy.html.
Your information will not be used for any other purpose, or shared any further, and will be destroyed when the member selection process is completed.
If you have any queries in relation to how your rights are upheld, please contact us at digitalhumanites@kcl.ac.uk, or KCL’s Information Compliance team at info-compliance@kcl.ac.uk).




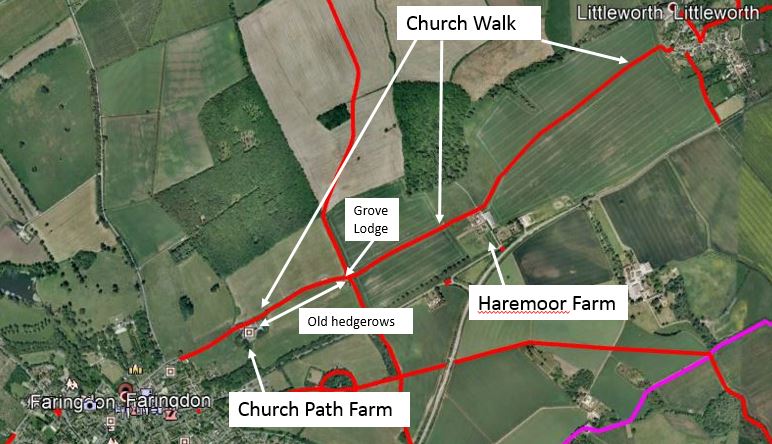


 significance, as these at least should preserve the orientation of the field. The slight difference between the path and the orientation suggests this field might have been sub-dived in to strips of a more south-westerly orientation than it is today, and that the path thus pre-dates it. The most obvious reason for this would be a change to accommodate the construction of London Street to the south, which connects Faringdon to the A420.
significance, as these at least should preserve the orientation of the field. The slight difference between the path and the orientation suggests this field might have been sub-dived in to strips of a more south-westerly orientation than it is today, and that the path thus pre-dates it. The most obvious reason for this would be a change to accommodate the construction of London Street to the south, which connects Faringdon to the A420.




